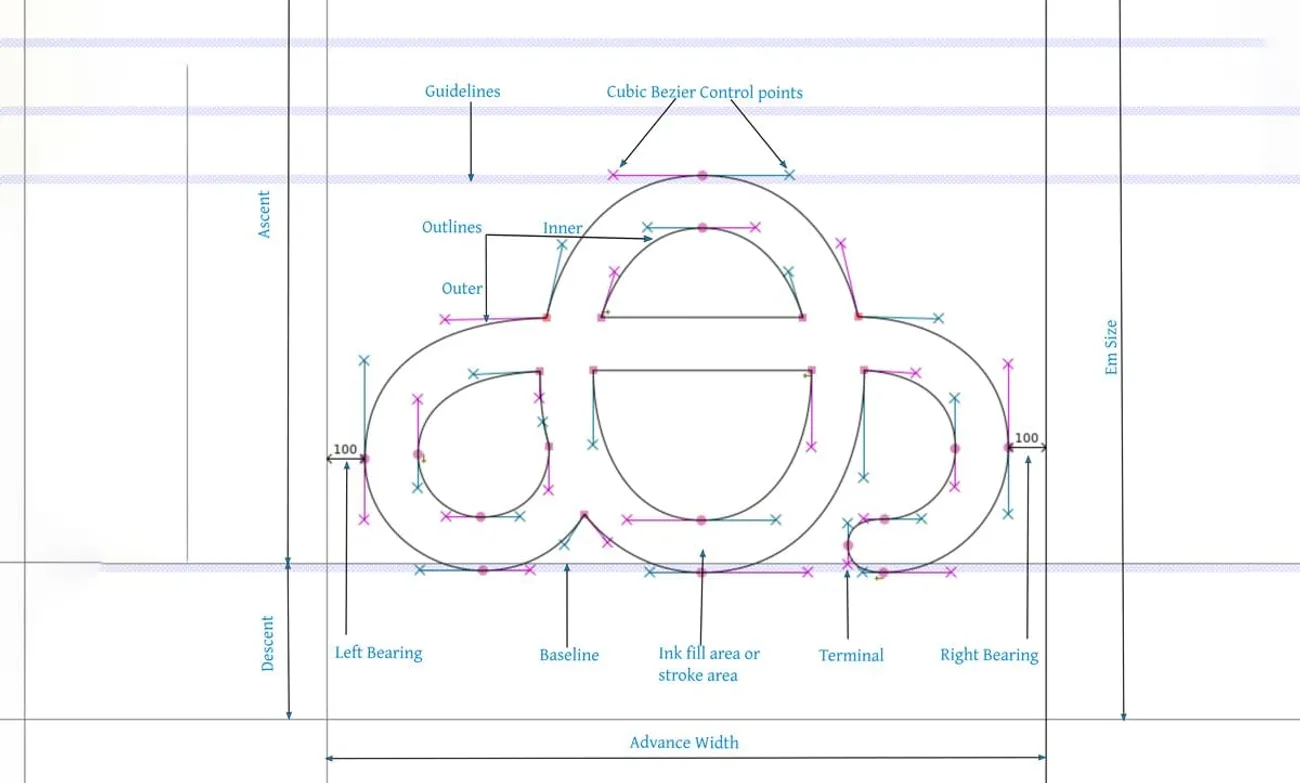
ഫോണ്ടുകളും ലിപിപരിഷ്കരണവും
നിലവിൽ പേന/ബ്രഷ് കൊണ്ടല്ലാത്ത എല്ലാത്തരം അച്ചടിയും അക്ഷരങ്ങളുടെ ചിത്രീകരണവും നടക്കുന്നത് ഫോണ്ടുകൾ എന്ന സോഫ്റ്റ്വെയർ വഴിയാണ്. അതുകൊണ്ടുതന്നെ ഒരു ഭാഷയിലെ ലിപിരൂപങ്ങളെക്കുറിച്ചുള്ള ഏതൊരുമാറ്റത്തിനും ഇന്ന് ഒരു സോഫ്റ്റ്വെയർ റിലീസ് സൈക്കിളിനോട് സാമ്യമുണ്ട്. പക്ഷേ പൂർണ്ണാർത്ഥത്തിൽ ഒരു സോഫ്റ്റ്വെയർ അതിന്റെ ഫീച്ചറുകളിൽ മാറ്റം വരുത്തി പുതിയ പതിപ്പായി ഇറക്കുന്നപോലെയല്ല ഫോണ്ടുകളുടെ റിലീസ്. ഫോണ്ടുകളിൽ ടെക്നോളജിയുടെ ഒപ്പം തന്നെ അക്ഷരങ്ങളുടെ കലാപരമായ ചിത്രീകരണം കൂടി ഉള്ളതുകൊണ്ട് ഒരിക്കൽ ഒരു ഫോണ്ട് പുറത്തുവന്നാൽ അതിന്റെ രൂപകല്പനയും ഘടനയും മാറ്റിപ്പണിത് പുറത്തിറക്കാറില്ല.
ഫോണ്ടിന്റെ ഐഡന്റിറ്റിയാണ് അതിലുള്ള ലിപിരൂപങ്ങളും അതിന്റെ എൻജിനിയറിങ്ങും. വേറൊരു രൂപകല്പനയും എൻജിനിയറിങ്ങും ആയി വേറെ ഫോണ്ടുകൾ വരും. ഫോണ്ടുകളാകട്ടെ ലോഹംകൊണ്ടുള്ള അച്ചുകളുടെ ഡിജിറ്റൽ രൂപമെന്ന ലളിതമായ നിർവചനത്തിൽനിന്നും വളരെയേറെ മുന്നേറിയിട്ടുമുണ്ട് (ഈ വിഷയത്തെപ്പറ്റിയുള്ള വിശദമായ വായനക്ക്: അക്ഷരങ്ങളുടെ ഡിജിറ്റൽ കാലം- അച്ചടിയിൽ നിന്ന് ഡിജിറ്റൽ ഫോണ്ടുകളിലെത്തിയ മലയാളത്തിന്റെ വർത്തമാനം- സന്തോഷ് തോട്ടിങ്ങൽ, അച്ചടി മലയാളത്തിന്റെ 200 വർഷങ്ങൾ). ഒരു ഫോണ്ടിൽ ഒരക്ഷരത്തിന് ഒറ്റ ലിപിരൂപമെന്ന ആശയം മാറിമറിഞ്ഞിട്ടുണ്ട്. ഓരോ ഫോണ്ടിന്റെയും ഡിസൈനർമാർ അവരുടെ ഫോണ്ടിനെ പരമാവധി വിവിധോദ്ദേശ ഫോണ്ടാക്കി മാറ്റാൻ ശ്രമിക്കും. ഉദാഹരണത്തിന് മഞ്ജരി, ഗായത്രി, ചിലങ്ക തുടങ്ങിയ മലയാളം ഫോണ്ടുകൾ സ്വതവേ പഴയലിപി ഫോണ്ടാണെങ്കിൽകൂടിയും അവ ഒരു പുതിയലിപി ഫോണ്ടായി ഉചിഹ്നങ്ങൾ വേർപെട്ടോ കൂട്ടക്ഷരങ്ങൾ വേർപെട്ടോ ഒക്കെ ഉപയോഗിക്കാനുള്ള മോഡ്യുലർ ഡിസൈനോടുകൂടി വരുന്നവയാണ്. ച്ച, ള്ള തുടങ്ങിയ അക്ഷരങ്ങൾക്കുള്ള പ്രാദേശിക വകഭേദങ്ങൾ ഇവയിലെല്ലാം അടങ്ങിയിട്ടുണ്ട്. അക്കങ്ങളുടെ വീതി ഒരു പട്ടികരൂപത്തിലെഴുതുമ്പോൾ ഒരേ വിതിയിൽ കണക്കുകൂട്ടാൻ പാകത്തിൽ വരാനും അങ്ങനെയല്ലാതെ വരാനുമുള്ള സാങ്കേതികവിദ്യകൾ ഇവയിലുണ്ട്. നോട്ടോ സാൻസ് മലയാളം എന്ന ഗൂഗിളിന്റെ മലയാളം ഫോണ്ടിലെ അക്ഷരങ്ങളുടെ കട്ടി (stroke width) ഒരാൾക്ക് ഇഷ്ടമുള്ള രീതിയിൽ മാറ്റം വരുത്താവുന്ന വിധമുള്ള വേരിയബിൾ ഫോണ്ടാണ്.
മേൽപ്പറഞ്ഞ ഫോണ്ടുകളെല്ലാം തന്നെ യുണിക്കോഡിന്റെ പതിനാലാം പതിപ്പിൽ നിർവചിച്ചിരിക്കുന്ന 118 അക്ഷരങ്ങളെയും (codepoint) ഉൾക്കൊണ്ട് സ്റ്റാൻഡേഡ് കമ്പാറ്റിബിൾ എന്നുപറയുന്നവയാണ്. ഈ 118 എണ്ണത്തിൽ മലയാളത്തിൽ ഇപ്പോൾ പ്രചാരമില്ലാത്ത നിരവധി അക്ഷരങ്ങൾ ഉണ്ട്.

പ്രചാരത്തിലുള്ള അക്ഷരങ്ങൾക്കപ്പുറം ലിപികളുടെയും കൂട്ടക്ഷരങ്ങളുടെയും വലിയ ശേഖരം ഫോണ്ടുകളിലുണ്ടാകും. യുണിക്കോഡ് സ്റ്റാൻഡേഡിലും അക്ഷരങ്ങളുടെ ചിത്രീകരണത്തെ സംബന്ധിച്ച ഓപ്പൺടൈപ്പ് സ്റ്റാൻഡേഡിലും ഇവയെ പരിഗണിക്കുന്നത് കാണാം. ഇതിനുള്ള കാരണം ഈ സ്റ്റാൻഡേഡുകളുടെ ലക്ഷ്യം അതാത് ഭാഷയിലെ പണ്ടുണ്ടായിരുന്നതും ഇപ്പോഴുള്ളതുമായ ഉള്ളടക്കത്തെ, അറിവിനെ, പരമാവധി രേഖപ്പെടുത്താൻ ശ്രമിക്കുകയെന്നതാണ്. യ എന്ന അക്ഷരത്തിനു ചില്ലുണ്ടായിരുന്നെന്നും അതിങ്ങനെയാണെന്നും കാണിക്കാൻ മാർഗ്ഗം വേണ്ടേ? ഗോപിരേഫം ഉപയോഗിച്ച് അർക്കൻ എന്നെഴുതാമെന്നു കാണിക്കേണ്ടേ? അളവുതൂക്ക ചിഹ്നങ്ങൾ വേണ്ടേ. അതുപോലെ തൂ എന്ന് ഊ ചിഹ്നം തൂവിനോട് ചേർക്കാമെന്ന് ഡിജിറ്റലായി രേഖപ്പെടുത്താനും ചിത്രീകരിക്കാനും കഴിയണം. തൂ എന്നുകൂടി അതിനെ ചിത്രീകരിക്കാമെന്നും. അക്ഷരങ്ങളുടെയും ലിപിരൂപങ്ങളുടെയും ഒരു സൂപ്പർസെറ്റായാണ് ഇവയെല്ലാം നിർവചിച്ചിരിക്കുന്നത്. പരമാവധി അവയെ ഉൾക്കൊള്ളാൻ ഫോണ്ടുകളും ശ്രമിക്കുന്നു.
ഇതുകൂടാതെ വിവിധതരം ഉപയോഗങ്ങൾക്കുള്ള പ്രത്യേക ഫോണ്ടുകൾ പുറത്തിറങ്ങുന്നുണ്ട്. ഉദാഹരണത്തിന് തലക്കെട്ടുകൾക്ക് വേണ്ടിയുള്ള ഫോണ്ട് ബോഡി ടെക്സ്റ്റിനു യോജിക്കില്ല. കുറഞ്ഞ സ്ഥലത്ത് അക്ഷരങ്ങളെ നന്നായി എടുത്തുകാട്ടുന്ന തലക്കെട്ടുഫോണ്ടുകളിൽ കൂട്ടക്ഷരങ്ങൾ കുറയ്ക്കാറുണ്ട്. പ്രത്യേകിച്ചും ഒന്നിനുമുകളിൽ ഒന്നായെഴുതുന്ന കൂട്ടക്ഷരങ്ങൾ (vertical stacking) - സ്ത എന്ന് സയുടെ അടിയിൽ ത എഴുതുന്ന ബോഡി ടെക്സ്റ്റ് ഫോണ്ട് ഉണ്ടാകാം. തലക്കെട്ടിൽ അത് സ്തു എന്ന് നിരത്തിയെഴുതുകയും ചെയ്യും. ഫോണ്ട് സോഫ്റ്റ്വെയർ ആയതുകൊണ്ട് ഇങ്ങനെയുള്ള പ്രത്യേകതരം കൂട്ടക്ഷരങ്ങളുടെ ചേരലും പിരിയലും കാണാം (Conditional clustering) .
ഇതിലെവിടെയാണ് മലയാളത്തിന്റെ പുതിയ ലിപി വരുന്നത്?
ഡാറ്റയെക്കുറിക്കുന്ന യുണിക്കോഡ് സ്റ്റാൻഡേഡിൽ മലയാളം പുതിയലിപി പഴയലിപി വേർതിരിവില്ല. ഏത് ലിപിയിലെഴുതിയാലും അതിനുള്ളിലെ ബിറ്റുകളുടെ കൂട്ടം ഒന്നുതന്നെയാണ്. എല്ലാവിധ മലയാളം കമ്പ്യൂട്ടിങ്ങ് അപ്ലിക്കേഷനുകളും പഴയലിപി, പുതിയലിപി വ്യത്യാസത്തിൽ നിന്നും സ്വതന്ത്രമാണ്. ഈ ഒരു വസ്തുത മലയാളം കമ്പ്യൂട്ടിങ്ങ് മനസ്സിലാക്കുന്നതിൽ ഏറ്റവും പ്രധാനപ്പെട്ടതായി കണക്കാക്കുന്നു. അതേ സമയം സാങ്കേതികവിദ്യയിൽ പരിചയക്കുറവുള്ളവർക്ക് മനസ്സിലാക്കാൻ വളരെയേറെ ബുദ്ധിമുട്ടുള്ളതുമാണ്. ലിപിവൈവിധ്യം മലയാളം കമ്പ്യൂട്ടിങ്ങുമായി ബന്ധപ്പെട്ടെ ഒരു സോഫ്റ്റ്വെയറിന്റെയും വിഷയമല്ല. ഒരാൾ പുതിയലിപിയിലെഴുതിത്തുടങ്ങിയാൽ അയാളുപയോഗിക്കുന്ന സോഫ്റ്റ്വെയർ പരിഷ്കരിക്കേണ്ട ആവശ്യമേയില്ല. ഡാറ്റ എങ്ങനെ നമ്മുടെ മുന്നിലെ സ്ക്രീനിൽ കാണുന്നു എന്നിടത്ത് അതാത് ഉപയോക്താക്കളുടെ വ്യക്തിപരമായ തിരഞ്ഞെടുപ്പുമാത്രമാണ് പഴയലിപി/പുതിയലിപി.
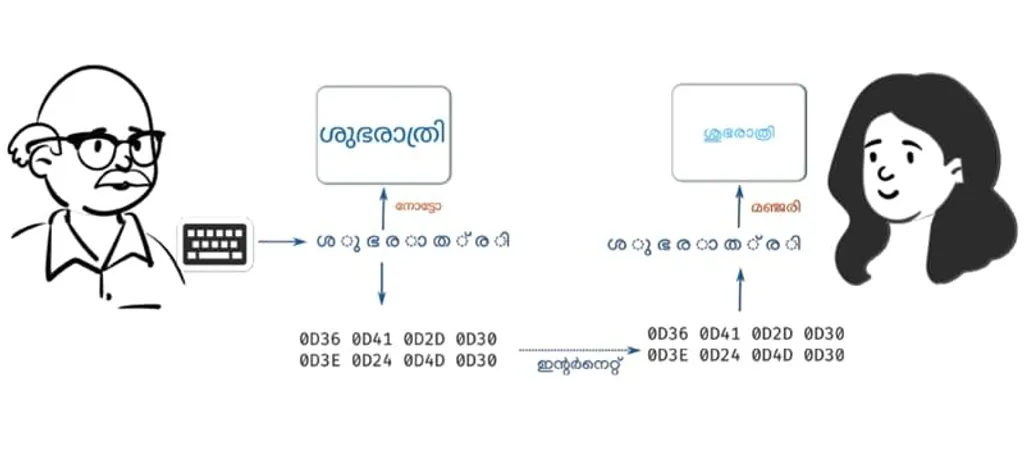
ഈയൊരു തിരഞ്ഞെടുപ്പിന്റെ സാധ്യതയിലാണ് ലോകത്തെ എല്ലാ ലിപികളിലും ഇന്ന് ലിപിപരിഷ്കരണം നിശബ്ദമായി നടക്കുന്നത്. ഒരു കാലഘട്ടത്തിലെ സംഗീതമോ സംസ്കാരമോ ജീവിതശൈലികളോ ഭക്ഷണരീതികളോ വസ്ത്രരീതികളോ എങ്ങനെയാണ് നിലവിൽവരുന്നത്? ആരെങ്കിലും ഇനിമുതലിങ്ങനെയാണെന്നു പറഞ്ഞിട്ടാണോ? അതാത്കാലത്ത് ഈ മേഖലകളിലുള്ളവർ നടത്തുന്ന പ്രവർത്തനങ്ങൾ-അവയിൽ ജനങ്ങൾ നടത്തുന്ന തിരഞ്ഞെടുപ്പുകൾ, അപ്പോളുണ്ടാകുന്ന ജനപ്രിയ ശൈലികൾ, രുചികൾ... ഇതുതന്നെയാണ് അക്ഷരങ്ങളുടെ സൗന്ദര്യത്തിന്റെയും ലിപികളുടെയും കാര്യത്തിൽ നടക്കുന്നത്. ഒരു ഫോണ്ടിനെ സംബന്ധിച്ചിടത്തോളം അതിന്റെ ഡിസൈനറാണ് അതിലുൾപ്പെടുത്തേണ്ട അക്ഷരങ്ങളേതൊക്കെയെന്നു തീരുമാനിക്കുന്നത്. അക്ഷരങ്ങളുടെ രൂപകല്പന സർഗ്ഗശേഷിയുടെ ആവിഷ്കാരമായതിനാൽ ചിലർ വിശാലമായ സാധ്യതകൾ തേടും. മലയാളത്തിന്റെ കാര്യത്തിൽ ഉ, ഋ എന്നിവയുടെ സ്വരചിഹ്നങ്ങളും കൂട്ടക്ഷരങ്ങളും ചേർന്ന വിശാലമായ അക്ഷരസഞ്ചയം ഈ സാധ്യതകൾ അവർക്കുമുന്നിൽ തുറന്നിടുന്നു. വാലിട്ട തു, ശയെ ചുറ്റിവരുന്ന ശ്ര, കുണുക്കിട്ട ണു, രണ്ട് ശ അടുക്കിയ ശ്ശ, പിരിക്കാതെയെഴുതിയ ന്മ, ക്ഷ, വളഞ്ഞുപുളഞ്ഞ ണ്ഡ - ഇതൊക്കെ തന്റെ ഫോണ്ടിൽ ഭംഗിയായി ആവിഷ്കരിക്കണമെന്നു ഒരു മലയാളി ഡിസൈനർക്ക് തോന്നാതിരിക്കുന്നതെങ്ങനെ? ഇതൊന്നുമില്ലാതെ ലിപിപരിഷ്കരണത്തിൽ പറയുന്നപോലെ നൂറിനടുത്ത് അക്ഷരങ്ങൾ മാത്രം വേർപെടുത്തി വരയ്ക്കുകയെന്നത് ടൈപ്പ് ഡിസൈനർമാർ ഇഷ്ടപ്പെടണമെന്നില്ല. മലയാളത്തിലെ നിലവിലുള്ള യുണിക്കോഡ് ഫോണ്ടുകളിൽ ഭൂരിപക്ഷവും ഇങ്ങനെ വിശാലമായ ലിപിസഞ്ചയമുള്ളവയാണെന്നത് ഇതിനു തെളിവാണ്. ചുരുങ്ങിയ അക്ഷരങ്ങളുള്ള ഫോണ്ടുകളാകട്ടെ കൊമേഴ്സ്യൽ കമ്പനികൾക്ക് വേണ്ടി വിദേശത്തുള്ള ടൈപ്പ് ഫൗണ്ടറികൾ നിർമിച്ചതുമാണ് (നോട്ടോ, വിൻഡോസിലെ നിർമല, മാക്കിന്റെ മലയാളം ഫോണ്ടുകൾ). എന്നിരിക്കിലും, പുതിയലിപി പിന്തുടരുന്ന ഗൂഗിളിന്റെ നോട്ടോയിൽ പോലും ക്ത, ക്ട, ക്ഷ, ഗ്ഗ, ഗ്മ, ഗ്ന, ച്ഛ, ജ്ജ, ഞ്ജ, ജ്ഞ, ണ്ഡ, ണ്മ, ത്ന, ത്ഭ, ത്മ, ത്സ, ത്ഥ, ല്പ, ശ്ശ, ഷ്ട, സ്സ, ശ്ച തുടങ്ങി 1971 ലെ ലിപിപരിഷ്കരണം ഒഴിവാക്കിയ നിരവധി കൂട്ടക്ഷരങ്ങൾ ഉണ്ടെന്നുള്ളതും ശ്രദ്ധേയമാണ്. നമ്മുടെ പത്രമാദ്ധ്യമങ്ങളും ഇത്തരം കൂട്ടക്ഷരങ്ങൾ ചേർത്താണല്ലോ അച്ചടിക്കുന്നത്.
ഫോണ്ടുകളുടെ രൂപകല്പന ഇന്നത്തെ കാലത്ത്, അത് സംസാരിക്കുന്ന ജനതയിൽ ഒതുങ്ങുന്നില്ല. ലോകത്ത് എവിടെയുമുള്ള ഒരാൾ മലയാളം ഫോണ്ട് രൂപകല്പന ചെയ്തുവെന്നും അത് ധാരാളം പേർ ഉപയോഗിക്കുന്ന ഒന്നായിമാറിയെന്നും വരാം. ഉദാഹരണത്തിന് ഓപ്പറേറ്റിങ്ങ് സിസ്റ്റങ്ങളുടെ കൂടെ സ്വതേവരുന്ന ഫോണ്ടുകൾ മലയാളികൾ ആയിരിക്കണമെന്നില്ല നിർമിച്ചിരിക്കുന്നത്.
ഒരു ഡിസൈനറുടെ ഓരോ ഫോണ്ടിന്റെയും രൂപകല്പന സ്വന്തം ഇഷ്ടാനിഷ്ടങ്ങളുടെയും ചരിത്രപരമായ സ്വാധീനങ്ങളുടെയും കൂടിച്ചേരലിന്റെ ഉത്പന്നമാണ്. ഇതുവരെ ആരും ചെയ്തിട്ടില്ലാത്ത പുത്തൻ രൂപകല്പന അവതരിപ്പിയ്ക്കാൻ എല്ലാ ഡിസൈനർമാരും ശ്രമിക്കാറുണ്ടെങ്കിലും അക്ഷരങ്ങളുടെ രൂപകല്പനയിൽ ഇതിനു പരിമിതിയുണ്ട്. എന്തൊക്കെ പരീക്ഷണങ്ങൾ ആണെങ്കിലും വായിക്കാനാകുകതന്നെവേണമല്ലോ. അതുകൊണ്ട് അതാതുകാലത്തെ കണ്ടുശീലിച്ച വായനാശീലങ്ങളിൽ നിന്ന് ചെറിയൊരു ചുവട് വെയ്ക്കുക മാത്രമാണ് ചെയ്യാൻ കഴിയുക. ആ ചെറുപരീക്ഷണത്തിൽ കാലഘട്ടത്തെയും സ്വന്തം കലാപരീക്ഷണത്തെയും ഡിസൈനർ അടയാളപ്പെടുത്താൻ നോക്കും. ഇതിൽ ചിലത് പരാജയപ്പെടും ചിലത് ജനകീയമാകും. ഒരു ജനത, ഒരു തലമുറ ആ അക്ഷരങ്ങൾ കണ്ടുവളരുമ്പോൾ അതുറച്ചുപോകും. ഇങ്ങനെ വിജയിക്കുന്നത് പഴയലിപിയാകാം, പുതിയലിപിയാകാം, മിക്കവാറും ഇവയുടെ ഏറ്റക്കുറച്ചിലുകളാകാം. അത് നിലനിൽക്കും, അതിനുമുകളിൽ അടുത്ത തലമുറ പുതിയ മുന്നേറ്റങ്ങൾ നടത്തും. ജനാധിപത്യപരമായ ഇത്തരം ലിപിപരിഷ്കരണങ്ങളേ ഇനി നടക്കുകയുള്ളൂ എന്നാണ് വിശ്വാസം. ഔദ്യോഗികാധികാരങ്ങൾകൊണ്ടുള്ള പരിഷ്കരണങ്ങളോ ഏതെങ്കിലും പ്രത്യേകശൈലിവേണമെന്ന മൗലികവാദങ്ങൾക്കോ പ്രസക്തിയുണ്ടെന്ന് കരുതുന്നില്ല. ഉപയോഗയോഗ്യതകൊണ്ടും ജനപ്രീതികൊണ്ടും ചില ഫോണ്ടുകൾ ഈ പരിഷ്കരണങ്ങളെ മുന്നോട്ട് നയിക്കും. അങ്ങനെയൊരു വിജയകരമായ ഫോണ്ടുനിർമിക്കാൻ കഴിഞ്ഞാൽ ലിപിപരിഷ്കരണത്തിൽ ഒരു ഡിസൈനർക്കു പങ്കാളിയാകാം.

യഥാർത്ഥത്തിൽ കഴിഞ്ഞ രണ്ടുപതിറ്റാണ്ടിൽ മലയാളത്തിൽ നടന്നതും ഇങ്ങനെയൊരു ലിപിപരിഷ്കരണമാണ്. മലയാളത്തിൽ രചന അക്ഷരവേദിയും സ്വതന്ത്ര മലയാളം കമ്പ്യൂട്ടിങ്ങും പുറത്തിറക്കിയ ഫോണ്ടുകൾ ആണ് ഇതിൽ പ്രധാനപങ്കുവഹിച്ചത്. പുതിയലിപി മാത്രം നിറഞ്ഞുനിന്നിരുന്ന, ആസ്കി ഫോണ്ടുകളുടെ പരിമിതികളുമായി ഡിടിപി സെന്ററുകളും പുസ്തകപ്രസാധകരും വ്യാപകമായി ഉപയോഗിച്ചിരുന്ന ആ ലിപിയിൽ നിന്നും പതിയെ വെബ്ബിലും പ്രസാധനത്തിലും പത്രങ്ങളിലും ഒക്കെ പഴയലിപി നിറയുന്നതിനു കഴിഞ്ഞ പതിറ്റാണ്ട് സാക്ഷ്യം വഹിച്ചിട്ടുണ്ട്. രചനയുടെയോ SMC യുടെയോ പഴയലിപി ഫോണ്ടുകൾ സാങ്കേതികമായോ സൗന്ദ്യര്യപരമായോ എന്തെങ്കിലും തരത്തിൽ മോശമായിരുന്നെങ്കിൽ ഈ പരിഷ്കാരം നടക്കില്ലായിരുന്നു. സാങ്കേതികത്തികവിന്റെയും മലയാളലിപിയോട് ചേർന്നുനിന്ന രൂപകല്പനയുടെ വിജയത്തിലുമാണ് ഈ മാറ്റം സാധ്യമായത്. സത്യത്തിൽ 2022ൽ ഒരു ലിപിപരിഷ്കരണചർച്ച പോലും വരാൻ കാരണം കമ്പ്യൂട്ടറുകളിൽ പ്രചാരത്തിലായ പഴയലിപിയാണെന്നു പറയാം. അതില്ലെങ്കിൽ നമ്മൾ 1971ലെ പരിഷ്കരണം തന്നെ തുടരില്ലായിരുന്നോ? രചനയുടെയും SMC യുടെയും ഫോണ്ടുകൾക്കൊപ്പം ജനങ്ങൾക്ക് ലഭ്യമായിരുന്നത് മൈക്രോസോഫ്റ്റ്, ഗൂഗിൾ, ആപ്പിൾ എന്നീ കമ്പനികളിറക്കിയ പുതിയലിപി ഫോണ്ടുകളായിരുന്നു. കമ്പ്യൂട്ടർ ഓപ്പറേറ്റിങ്ങ് സിസ്റ്റങ്ങളിലും ഫോണുകളിലും ബിൽറ്റിൻ ആയി വന്ന ആ ഫോണ്ടുകൾക്കുമുകളിൽ പഴയലിപി പ്രചാരത്തിലായത് വലിയൊരു ലിപിപരിഷ്കാരമായിത്തന്നെ അടയാളപ്പെടുത്തണം. നവമാധ്യമങ്ങളിലെ ട്രോളുകളിലും മീമുകളിലും, ഒപ്പം ചുമരെഴുത്തുകളിലും നിറഞ്ഞുനിന്ന ലിപിയാണ് സ്കൂളുകൾ പുറത്താക്കിയ പഴയലിപിയെ പുതിയതലമുറയ്ക്ക് പരിചയപ്പെടുത്തിയത്. ഈ മാറ്റത്തിനു ഒരുവിധത്തിലുള്ള ഔദ്യോഗികസ്വഭാവവും ഇല്ലായിരുന്നു. ഒരു സർക്കാർ ഉത്തരവുമില്ല. ആരെയും നിർബന്ധിച്ചിട്ടുമില്ല.
മാനകീകരണം
ഇതിനൊപ്പം ഡിജിറ്റൽ ടൈപ്പോഗ്രഫിയുടെ സാങ്കേതികതയിലും ലിപിസംബന്ധിയായ നിയമങ്ങളിലും മാനകീകരണം കൊണ്ടുവരികയെന്ന വലിയൊരു ദൗത്യം കൂടി മേൽപ്പറഞ്ഞ ഫോണ്ടുകളിലൂടെ നടന്നിട്ടുണ്ട്. മലയാളലിപിയുടെ ഓപ്പൺ ടൈപ്പ് എൻജിനിയറിങ്ങിന്റെ Best practice ആയും Reference Implementation ആയും ഈ ഫോണ്ടുകൾ പ്രചാരത്തിലായി. ലിപി സങ്കീർണത സാങ്കേതികവിദ്യയിൽ എങ്ങനെ പരിഹരിക്കപ്പെട്ടുവെന്ന് വിശദമായ ലേഖനങ്ങളിലൂടെ സന്നദ്ധപ്രവർത്തകർ രേഖപ്പെടുത്തി, അവ നിരവധി വേദികളിൽ അവതരിപ്പിച്ചു. സ്വതന്ത്ര ലൈസൻസിൽ ഫോണ്ടുകളുടെ വരകളും കോഡും ബിൽഡിങ്ങ് സിസ്റ്റവും എല്ലാവർക്കും പഠിക്കാനും അതിനുമുകളിൽ പുതിയ ഫോണ്ടുകൾ നിർമിക്കാനും വേണ്ടി പങ്കുവെച്ചു. Unicode, Opentype rendering engines തുടങ്ങിയ അനുബന്ധ സംവിധാനങ്ങളിൽ മലയാളത്തിന്റെ കുറ്റമറ്റ ചിത്രീകരണം ഉറപ്പുവരുത്താൻ അത്തരം സംരംഭങ്ങളുമായി സഹകരിച്ചുപ്രവർത്തിച്ചു. ഇന്ന് മലയാളികൾ ആസ്വദിക്കുന്ന, ഉപയോഗിക്കുന്ന ഫോണുകളിലും കമ്പ്യൂട്ടറുകളിലുമുള്ള മലയാളം ഇത്തരത്തിലുള്ള വലിയൊരു പ്രവർത്തനത്തിന്റെ ഫലംകൂടിയാണ്.
ഡിജിറ്റൽ കാലത്തെ ലിപികളുടെ സ്വഭാവം ഇങ്ങനെയായിരിക്കെ ഒരു സ്റ്റാൻഡേഡൈസേഷൻ കമ്മിറ്റിയുടെ റോൾ എന്താകണം? സർക്കാർതലത്തിൽ ഒരു ലിപിപരിഷ്കാരം കൊണ്ടുവരികയാണെങ്കിൽ അതെങ്ങനെയായിരിക്കണം?
ലിപിപരിഷ്കരണത്തിന്റെ സമീപനനയം
ലിപി മാത്രമല്ല, പൊതുവിൽ സമൂഹത്തിൽ സംഭവിക്കുന്ന ഭാഷയുടെ പരിണാമങ്ങളെ അടയാളപ്പെടുത്താനും മാനകങ്ങളുണ്ടാക്കാനും രണ്ടുരീതിയിലുള്ള സമീപനങ്ങളാണ് കണ്ടുവരുന്നത്. നിർദ്ദേശാത്മക സമീപനം (prescriptive approach), വിവരണാത്മക സമീപനം (descriptive approach). ഇപ്പോൾ സർക്കാർ രൂപീകരിച്ച വിദഗ്ദ്ധസമിതിയും സമിതിയുടെ നിർദ്ദേശങ്ങളും നിർദ്ദേശാത്മക സമീപനമാണ് പിന്തുടരുന്നത്. അവിടെ സർക്കാർ അതിന്റെ അധികാരം ഉപയോഗിക്കുകയും ലിപിയുടെ ഉപയോഗം ഇന്നതാകണമെന്ന് ജനങ്ങളോട് നിർദ്ദേശിക്കുകയും ചെയ്യുന്നു. നിർദ്ദേശങ്ങൾക്കാസ്പദമായ പ്രശ്നങ്ങളെയോ, പരിഹാരത്തിനായി ചെയ്ത പഠനങ്ങളെയോ സംബന്ധിച്ചുള്ള സുതാര്യത, സമിതിയുടെ നിർദ്ദേശങ്ങൾക്കുമേൽ പൊതുജനങ്ങൾക്ക് എങ്ങനെ അഭിപ്രായം രേഖപ്പെടുത്താനും സ്വാധീനിക്കാൻ കഴിയുമെന്നതെല്ലാം പരിമിതമാണ്. കൂടാതെ ലിപിയുടെ സമകാലിക ഉപയോഗത്തെയോ അതിന്റെ വരുംകാലസ്വഭാവത്തെയോ പൂർണ്ണമായി പഠിക്കാതെയും ലിപിയുടെ ചില ഭാഗങ്ങളെ തള്ളിക്കളഞ്ഞുമാണ്(Exclusion) ഇപ്പോൾ നിർദ്ദേശങ്ങൾ പുറത്തുവന്നിട്ടുള്ളത്. നിർദ്ദേശാത്മക സമീപനം ഇന്നത്തെക്കാലത്ത് വിജയിക്കുന്നത് അതുകൊണ്ടുവരുന്ന സർക്കാറിന്റെ അധികാരശക്തിയെ വല്ലാതെ ആശ്രയിച്ചിരിക്കും. മുകളിൽ വിവരിച്ച ലിപിപരിഷ്കരണത്തിൽ സമൂഹത്തിന്റെയും സാങ്കേതികവിദ്യയുടെയും ഇടപെടലിനെ അംഗീകരിക്കാനോ അടയാളപ്പെടുത്താനോ സമിതി ശ്രദ്ധിച്ചിട്ടില്ലെന്നതുകൂടി ശ്രദ്ധേയമാണ്. സമിതിയിൽ സാങ്കേതികവിദ്യയുമായി ബന്ധമുള്ളവരാരുംതന്നെയില്ല. ഇന്നത്തെ വിവരവ്യവസ്ഥ(information system) നിലനിൽക്കുന്ന അന്താരാഷ്ട്ര സാങ്കേതിക സ്റ്റാൻഡേഡുകളെപ്പറ്റിയോ അവയുമായി സമിതിയുടെ നിർദ്ദേശങ്ങൾ പൊരുത്തപ്പെട്ടുപോകേണ്ടതിന്റെയോ ധാരണ ഉണ്ടെന്നുകരുതുന്നില്ല.
ഇന്നത്തെ സാഹചര്യത്തിൽ വിവരണാത്മക സമീപനമാണ് ഗവൺമെന്റ് സ്വീകരിക്കേണ്ടിയിരുന്നത്. ഭാഷയുടെയും ലിപിയുടെയും സമകാലിക ഉപയോഗത്തെപ്പറ്റിയും അതിന്റെ സ്വഭാവത്തെപ്പറ്റിയും പഠിക്കുകയും അവ പ്രസിദ്ധീകരിക്കുകയും ചെയ്യുക. നിലനിൽക്കുന്ന, പ്രചാരത്തിലുള്ള ലിപിയെ വ്യക്തമായി ഡോക്യുമെന്റ് ചെയ്യുക. ആ ലിപിയിലുള്ള മലയാളഭാഷയുടെ ഉപയോഗത്തെപ്പറ്റി ഗൈഡ് ലൈൻസ് രൂപീകരിക്കുക. അതിനുമുകളിൽ സാങ്കേതികവിദ്യ തയ്യാറാക്കുന്നവർക്കുള്ള സഹായകരേഖകൾ പ്രസിദ്ധീകരിക്കുക. വിദ്യാർത്ഥികൾ ഈ ലിപി പരിചയപ്പെടാനുള്ള മാർഗങ്ങൾ പാഠ്യപദ്ധതിയിൽ കൊണ്ടുവരിക എന്നിവയൊക്കെയാണ് വിവരണാത്മക സമീപനത്തിൽ ചെയ്യുക. പുതിയലിപിയും പഴയലിപിയും നിലനിൽക്കുന്ന ഒരു ഭാഷായാഥാർത്ഥ്യത്തെ അടയാളപ്പെടുത്തുക. ഇതിൽ ഏതെങ്കിലുമൊന്നിന് മറ്റൊന്നിനേക്കാൾ മേൽക്കൈയുണ്ടെങ്കിൽ തന്നെ അത് മാറ്റങ്ങൾക്ക് വിധേയമാണെന്നും കാലാകാലം അത് നിരീക്ഷിക്കേണ്ടതാണെന്നും തിരിച്ചറിയുക. അതിലേക്കെത്തിച്ചേന്ന നാൾവഴിയെന്തെന്ന് പഠിക്കുക, പ്രസിദ്ധീകരിക്കുക. മലയാളഭാഷയ്ക്കുള്ള ഫോണ്ടുകളും സോഫ്റ്റ്വെയറും നിർമിക്കുന്ന മലയാളികൾ മാത്രമല്ലെന്നും കേരളത്തിൽ മാത്രമല്ലെന്നും നേരത്തെ സൂചിപ്പിച്ചു. വിവിധ സോഫ്റ്റ്വെയർ സംവിധാനങ്ങളിൽ മലയാളം കൃത്യമായി പിന്തുണയ്ക്കണമെങ്കിൽ അതെങ്ങനെവേണമെന്നുള്ള ഡോക്യുമെന്റേഷൻ വേണം. നിലവിൽ അങ്ങനെയൊന്നില്ല, പകരം Reference implementations ആണ് ഉള്ളത്. അതായത് പൊതുവിൽ നല്ലരീതിയിൽ പ്രവർത്തിക്കുന്ന ഫോണ്ടുകളെയും സോഫ്റ്റ്വെയറുകളെയും റെഫർ ചെയ്യുന്നു. ഇത്തരം റെഫറൻസുകൾ ഭാഷാവിദഗ്ധരും സാങ്കേതികവിദഗ്ധരും തയ്യാറാക്കി പ്രസിദ്ധീകരിക്കേണ്ടതിന്റെ വലിയ ആവശ്യമുണ്ട്. മലയാളത്തിനുവേണ്ടിയുള്ള സോഫ്റ്റ്വെയറും ഫോണ്ടുകളുമെല്ലാം ആരെങ്കിലും ചെയ്തോളും എന്ന ഉദാസീനനയം വിട്ട്, ഇത് നമ്മുടെ വിദ്യാർത്ഥികളെ പരിശീലിപ്പിക്കാനും ഭാഷാപഠനപദ്ധതി പരിഷ്കരിക്കാനും വിവരണാത്മക മാനകരേഖകൾ വേണം.
വിവരണാത്മക സമീപനത്തിൽ ഏതെങ്കിലും ലിപിരൂപങ്ങളെ തള്ളിക്കളയേണ്ടതോ റദ്ദുചെയ്യേണ്ടതോ ആയ ആവശ്യമില്ല. അങ്ങനെ ചെയ്യാനാകില്ല എന്നതാണ് യാഥാർത്ഥ്യം. ഏതെങ്കിലും ലിപിശൈലിയെ പ്രോത്സാഹിപ്പിക്കാം. എതെങ്കിലും ഒരു കാലത്ത് എവിടെയെങ്കിലും ഒരു ശൈലി ഉപയോഗിച്ചിരുന്നെങ്കിൽ നമുക്ക് അതിനെപ്പറ്റി ചർച്ച ചെയ്യണം, പഠിക്കണം. അതിന് ആ ലിപി രേഖപ്പെടുത്താൻ പറ്റണം, അതിനുള്ള സാങ്കേതികവിദ്യ വേണം. ഒരു ലിപിയും പെട്ടെന്ന് അപ്രത്യക്ഷമാകുന്നുമില്ല.
ലിപിപഠനം
ഉ, ഊ ചിഹ്നങ്ങൾ ചേർത്തെഴുതരുതെന്ന നിർദ്ദേശത്തിന്റെ കാരണം അത് കുട്ടികളിൽ ആശയക്കുഴപ്പമുണ്ടാക്കും എന്നതാണെന്നു കാണുന്നു. വ്യഞ്ജനങ്ങളുടെ ഉ-സ്വരചിഹ്നം ചേർന്ന രൂപങ്ങൾക്ക് ഒരുമയില്ലെന്ന കാരണവും ചൂണ്ടിക്കാണിക്കുന്നു. കുട്ടികളിൽ ഇത് ആശയക്കുഴപ്പമുണ്ടാക്കുന്നുവെന്നത് ഒരു അഭിപ്രായമാണോ അതോ ഏതെങ്കിലും പഠനത്തിലൂടെ തെളിഞ്ഞതാണോയെന്ന് പരിശോധിക്കേണ്ടതുണ്ട്. ഉ-ചിഹ്നങ്ങൾ ചേർന്ന രൂപം സ്കൂളുകളിൽ പഠിപ്പിക്കുന്നില്ല. പാഠപുസ്തകങ്ങളിലുമില്ല. പക്ഷേ പഠിക്കാത്ത ഈ അക്ഷരരൂപങ്ങൾ നമുക്ക് ചുറ്റും എവിടെയും കാണുന്നുമുണ്ട്. കുട്ടികൾ അത് കണ്ട് പരിചയിക്കുന്നു, എഴുതാൻ ശ്രമിക്കുന്നു. പാഠ്യപദ്ധതി പുറത്തുനിർത്തിയ അക്ഷരങ്ങൾ കുട്ടികൾക്ക് ആശയക്കുഴപ്പമുണ്ടാക്കുന്നുവെന്നു പറയുന്നതിൽ നിരവധി പ്രശ്നങ്ങളില്ലേ? ഒന്നാമതായി അക്ഷരപഠനത്തെ സംബന്ധിച്ച വിചിത്രമായ ഒരു പോരായ്മ ഇവിടെ തുറന്നുകാട്ടപ്പെടുന്നു. ഒരു കുട്ടി ചുറ്റുമുള്ള സമൂഹത്തിൽ കാണുന്ന മാതൃഭാഷയിലെ അക്ഷരങ്ങൾ സ്കൂളിൽ പഠിക്കാത്തതാണെന്ന അവസ്ഥ എത്രത്തോളം വിചിത്രമാണ്? എന്നിട്ടും ആ കുട്ടികൾ ആ ലിപികൾ സ്വായത്തമാക്കാൻ ശ്രമിക്കുന്നു, എഴുതാൻ ശ്രമിക്കുന്നു, ചിലപ്പോഴൊക്കെ തെറ്റുന്നു. സ്കൂൾതലത്തിൽ നടക്കുന്നു സാഹിത്യമത്സരങ്ങളിലെ രചനകൾ പരിശോധിച്ചാൽ വ്യക്തമാകുന്ന ഒരു കാര്യം സ്കൂളിൽ പഠിക്കുന്നലിപിയും പ്രായോഗികമായി ഒരു കുട്ടി എഴുതുന്ന ലിപിയും തമ്മിലുള്ള അന്തരമാണ്. ഈ യാഥാർത്ഥ്യം പാഠ്യപദ്ധതി മനസ്സിലാക്കിയിട്ടില്ലെങ്കിലും ജനപ്രിയ കലാരൂപങ്ങൾ ഏന്നേ മനസ്സിലാക്കിയിട്ടുണ്ട്. അടുത്തിടെയിറങ്ങിയ സിനിമകളുടെ ടൈറ്റിലുകൾ ശ്രദ്ധിക്കുക. അവയുടെ പരസ്യം ശ്രദ്ധിക്കുക. കഴിഞ്ഞ ക്രിസ്മസ് കാലത്ത് ഇറങ്ങിയ മിന്നൽ മുരളിയെന്ന സിനിമയുടെ പരസ്യത്തിനുപയോഗിച്ചത് പഴയലിപിയിലെ ഒരു കോമിക് ആയിരുന്നു. പത്രങ്ങളിൽ മുൻപേജിൽ വന്നിരുന്നു. യുറിക്ക ധാരാളമായി പഴയലിപി ഉപയോഗിച്ച് അച്ചടിക്കുന്നു. ബാലഭൂമി, കളിക്കുടുക്ക, കുട്ടികളുടെ ദീപിക തുടങ്ങിയ ബാലപ്രസിദ്ധീകരണങ്ങളുടെ ടൈറ്റിലുകൾ തന്നെ ഇത്തരം ഉചിഹ്നങ്ങൾ ഉപയോഗിക്കുന്നവയാണ്.
പ്രചാരത്തിലുള്ള ഭാഷയിലെ ലിപികളുടെ ഒരു ഉപഗണത്തെ മാത്രം(അതിനി പഴയലിപിയായാലും പുതിയലിപിയായാലും) പഠിപ്പിക്കുന്നത് അശാസ്ത്രീയമാണ്. മറ്റുളളവർ എഴുതുന്നത് വായിക്കാൻ പൂർണ്ണമായും കഴിവുള്ളവരാവണം നമ്മുടെ കുട്ടികൾ. അതിനുവേണ്ടി ശാസ്ത്രീയമായിത്തന്നെ ലിപി പരിചയപ്പെടുത്തുകയാണ് വേണ്ടത്. ആദ്യം ലളിതമായ അക്ഷരങ്ങളിൽ നിന്ന് തുടങ്ങി സങ്കീർണ്ണമായ അക്ഷരങ്ങളിലേക്ക് എത്തണം. ഇത് ലോകത്തിൽ പല ലിപികൾക്കും ഉള്ള സ്വഭാവം തന്നെയാണ്. ലിപിയുടെ ഈ വൈവിദ്ധ്യത്തെ ഉൾക്കൊള്ളാൻ തയ്യാറാകണം.
ഉ ചിഹ്നങ്ങൾ എഴുതുന്നതിൽ ഒരുമയില്ലെന്ന കാര്യം പറയുമ്പോൾ ലിപിയ്ക്ക് വളരെ യുക്തിഭദ്രമായ രൂപമുണ്ടെന്ന തെറ്റിദ്ധാരണയാണെന്നു തോന്നുന്നു. നമ്മുടെ ലിപി നിർമിതലിപിയല്ല, അത് പരിണമിച്ചുണ്ടായതാണ്. ഈ, ഊ എന്നിവയുടെ ദീർഘമെഴുതാൻ ൗ ചിഹ്നമുപയോഗിക്കുന്നതിൽ യുക്തി കാണുന്നുണ്ടോ? ഓ എന്നെഴുതാൻ ാ ചിഹ്നമുപയോഗിക്കുന്നു. അതേ സമയം ആ, ഏ എന്നെഴുതാൻ ചിഹ്നമൊന്നുമില്ലതാനും. വ്യഞ്ജനങ്ങളാകട്ടെ ചിലത് ചേർന്ന് കൂട്ടക്ഷരമുണ്ടാകുന്നു. ചിലവ ചേരുന്നില്ല, പിരിച്ചെഴുതുന്നു. ച്ച, വ്വ, യ്യ, ബ്ബ എന്നിവയുടെ ഇരട്ടിച്ച രൂപം നോക്കൂ. അതുപോലെയാണോ ല്ല എന്നിരട്ടിക്കുന്നത്? വേറെ കുറേ വ്യഞ്ജനങ്ങൾ ഇരട്ടിക്കുമ്പോൾ ഒന്നിനുമുകളിൽ ഒന്നായെഴുതുന്നു(സ്സ, ശ്ശ, പ്പ), മറ്റുചിലവ നിരത്തിയെഴുതുന്നു(ക്ക, മ്മ, ന്ന).ഇതിലൊക്കെ കുട്ടികൾക്ക് പെട്ടെന്നു പഠിക്കാവുന്ന യുക്തിയുണ്ടോ? തമിഴിൽ ഉ-ചിഹ്നങ്ങൾ എഴുതുന്നതിലും മലയാളത്തിനുസമാനമായ വൈവിധ്യം ഉണ്ട്. തമിഴ് ലിപി ലളിതമാക്കിയെങ്കിലും ഉ ചേർത്തെഴുതുന്ന ശൈലി ഇപ്പോഴും തുടരുന്നു.
വ്യക്തമായ പഠനമില്ലാതെ ഇതൊക്കെ കുട്ടികൾക്ക് പഠിക്കാൻ ബുദ്ധിമുട്ടുണ്ടെന്നു പറയുന്നത് മുതിർന്നവരുടെ അഭിപ്രായം മാത്രമാണ്.
ലിപി മൗലികവാദം
ഏതെങ്കിലും ഒരു പ്രത്യേകശൈലി തനത്, സമഗ്രം, ശുദ്ധം, പരമ്പരാഗതം തുടങ്ങിയ വിശേഷണങ്ങളോടെ പ്രത്യേക മേന്മ അവകാശപ്പെടുകയും അതല്ലാത്തവയെ തള്ളിക്കളയുന്നതുമായ ലിപി മൗലികവാദം ഒട്ടും ആശാസ്യമല്ല. ജനങ്ങളുടെ അഭിരുചികളെയും ഉപയോഗശീലങ്ങളെയും സ്വാധീനിക്കാം, പക്ഷേ അടിച്ചേൽപിക്കാൻ പറ്റില്ല. ഇത്തരം ആശയങ്ങളുള്ളവർ സർക്കാർ സമിതിയിലെ വ്യക്തികളെയും അവഹേളിക്കുന്നതുകണ്ടു. അതിനോടും വിയോജിക്കുന്നു.
സമിതിയുടെ നിർദ്ദേശങ്ങളെക്കുറിച്ച്
ലിപി പരിഷ്കരണത്തിനു നിയോഗിച്ച സമിതിയെയും അതിന്റെ നിർദ്ദേശങ്ങളെയും കുറിച്ചുള്ള നിരീക്ഷണങ്ങൾ:
1) സർക്കാറിന്റെ 1971ലെ ലിപിപരിഷ്കരണം ഉദ്ദേശിച്ചതിൽനിന്നും വ്യത്യസ്തമായി പഴയലിപി പ്രചാരത്തിലായതാണ് ഈ സമിതി രൂപീകരിക്കാനുണ്ടായ പ്രധാനകാരണമെന്നത് സ്വാഗതാർഹമാണ്. ജനങ്ങൾ കൊണ്ടുവന്ന ലിപിയുടെ ഈ മാറ്റത്തെ തിരിച്ചറിഞ്ഞ് അതിനെ നിർവചിക്കുന്നത് എന്തുകൊണ്ടും നല്ലതാണ്. ഈ തിരിച്ചറിവിന്റെ വിപരീതദിശയിൽ, ജനങ്ങൾ ലിപിയിൽ ചില മാറ്റങ്ങൾ വരുത്തണമെന്നു നിർദ്ദേശിക്കുന്നതാകട്ടെ ആശങ്കയുണ്ടാക്കുന്നതുമാണ്.
2) ഏതൊക്കെ പ്രശ്നങ്ങളാണ് ലിപിയിൽ ഇന്നുള്ളത് എന്നും ആ പ്രശ്നങ്ങൾ നിലനിൽക്കുന്നുവെന്നതിനാധാരമായ തെളിവുകളും സമിതി പ്രസിദ്ധീകരിക്കേണ്ടതുണ്ട്. പ്രശ്നങ്ങളുണ്ട് എന്ന ജനങ്ങൾക്ക് ബോധ്യപ്പെടാത്തിടത്തോളം പരിഹാരങ്ങളും ബോധ്യപ്പെടില്ല. നിർദ്ദേശങ്ങൾ എങ്ങനെ ഈ പ്രശ്നത്തെ പരിഹരിക്കും എന്നും വിശദമാക്കേണ്ടതുണ്ട്. ലിപിവൈവിധ്യം പ്രശ്നമാണെങ്കിൽ പുതിയ ശൈലി നിർദ്ദേശിക്കുന്നത് വൈവിധ്യത്തെ കൂട്ടുകയേയുള്ളൂവെന്ന നിരീക്ഷണത്തിനുത്തരം നൽകണം.
3) സമിതിയുടെ നിർദ്ദേശങ്ങൾക്ക് ആസ്പദമായ പഠനങ്ങളോ ഡാറ്റയോ ലഭ്യമല്ല. വിദഗ്ധരാണെന്നതുകൊണ്ടുമാത്രം നിർദ്ദേശങ്ങൾ നല്ലതാണെന്നു കരുതാനാകില്ല. കുറേ വർഷങ്ങൾക്കു ശേഷം തിരിഞ്ഞുനോക്കുമ്പോൾ നിർദ്ദേശങ്ങളും സമിതി അംഗങ്ങളുടെ പട്ടികയും മാത്രമാകരുത് ശേഷിക്കുന്നത്. അന്ന് ഏതൊരാൾക്കും ഈ പഠനങ്ങളെയും ഡാറ്റയും വെച്ച് ആലോചിച്ചാൽ സമിതി ഇന്ന് നിർദ്ദേശിച്ചവയിൽ എത്തിച്ചേരാൻ കഴിയണം.
4) 1971 ലെ ലിപിപരിഷ്കരണനിർദ്ദേശങ്ങൾക്ക് എന്തു സംഭവിച്ചുവെന്ന പഠനവും അതിൽ നിന്നുള്ള പാഠങ്ങളും സമിതി പ്രസിദ്ധികരിക്കണം. ആ നിർദ്ദേശങ്ങൾ പിൻവലിക്കുന്നുണ്ടൊയെന്നും വ്യക്തമാക്കേണ്ടതുണ്ട്.
നിർദ്ദേശങ്ങൾ സമഗ്രമല്ല. ഭാഷയുടെ ഉപയോഗത്തെപ്പറ്റി ചില നിർദ്ദേശങ്ങൾ ഉണ്ടെങ്കിലും ഭാഷാ ഉപയോഗത്തിലെ ചില പ്രശ്നങ്ങൾ മാത്രമാണ് അവ ചർച്ച ചെയ്യുന്നത്. ലിപികൾ ഏതൊക്കെയാണെന്ന് പട്ടികയുണ്ടെങ്കിലും അതിൽ ഇല്ലാത്ത പ്രചാരത്തിലുള്ള നിരവധി കൂട്ടക്ഷരങ്ങൾ വേറെയുമുണ്ട്. മാത്രമല്ല.്ര ചിഹ്നം ചേർത്തെഴുതണമെന്നു പറയുമ്പോൾ സ്ത എന്ന കൂട്ടക്ഷരം സ്ത്ര എന്ന കൂട്ടക്ഷരം വീണ്ടുമുണ്ടാക്കുമെന്ന് പരിഗണിച്ചിട്ടില്ല.
1991 ൽ യുണിക്കോഡ് നിലവിൽ വന്നു. മലയാളത്തിലെ അക്ഷരങ്ങൾക്ക് കോഡ് പോയിന്റുകൾ വന്നു. ഇക്കഴിഞ്ഞ 30 വർഷങ്ങളിൽ കമ്പ്യൂട്ടറിൽ മലയാളഭാഷയുടെ ഉപയോഗം എത്ര പുരോഗമിച്ചു? അക്ഷരമാലയിൽ എത്ര അക്ഷരങ്ങളുണ്ടെന്നു തർക്കങ്ങൾ നടക്കുമ്പോൾ മലയാളത്തിന്റെ പ്രാചീനരേഖകൾ തപ്പിയെടുത്ത് എങ്ങനെയൊക്കെ മലയാളം എഴുതിയിരുന്നോ അതൊക്കെ ഡോക്യുമെന്റ് ചെയ്ത് അതിലെ അക്ഷരങ്ങൾക്കെല്ലാം കോഡ് പോയിന്റ് കൊടുത്ത് 118 കോഡ് പോയിന്റുള്ള മലയാളം യുണിക്കോഡ് ആയി ഇന്ന് എത്തിയത് സന്നദ്ധപ്രവർത്തകരുടെ മാത്രം പ്രവർത്തനഫലമാണ്. സങ്കീർണ്ണലിപിവ്യവസ്ഥയുള്ള ദ്രാവിഡഭാഷകളുടെയൊപ്പം മലയാളത്തിന്റെ അക്ഷരങ്ങളുടെ ചിത്രീകരണനിയമങ്ങൾ കമ്പ്യൂട്ടറിനെ ``പഠിപ്പിച്ച്' ഓപ്പൺടൈപ്പ് എൻജിനിയറിങ്ങിലൂടെ കുറ്റമറ്റ മലയാളം ചിത്രീകരണം ഇന്ന് സാധ്യമായത് സന്നദ്ധപ്രവർത്തകരുടെയും സോഫ്റ്റ്വെയർ കമ്പനികളുടെയും ശ്രമഫലമായാണ്. കുറേയൊന്നുമില്ലെങ്കിലും പരമാവധി സാങ്കേതികത്തികവോടെ മലയാളത്തിന്റെ അക്ഷരങ്ങളെ വരച്ചെടുത്ത് ഫോണ്ടുകളാക്കി സൗജന്യമായി സ്വതന്ത്രമായി മലയാളത്തിനു സമ്മാനിച്ചതും സന്നദ്ധപ്രവർത്തകരാണ്. ജനങ്ങൾ അവയെല്ലാം സ്വീകരിച്ച് ടെക്നോളജിയുടെ പുതിയ പടവുകൾ കയറുമ്പോഴും നമ്മുടെ അക്കാദമികലോകവും ഗവൺമെന്റും കാഴ്ചക്കാരായിരുന്നു. ഇപ്പോൾ ഉപയോക്താക്കളും. ഈ മുപ്പതുവർഷത്തിൽ ഭാഷാസാങ്കേതികരംഗത്ത് നടന്ന ഭാഷാചർച്ചകളുടെ ആഴമോ പരപ്പോ അക്കാദമികസമൂഹത്തിൽ നടന്നെന്നു തോന്നുന്നില്ല. പക്ഷേ 2022 ൽ ഈ ടെക്നോളജിയും ലിപികളും എങ്ങനെയാകണമെന്ന് നിർദ്ദേശങ്ങൾ പുറപ്പെടുവിക്കാനും അതിൽ സാങ്കേതികവിദഗ്ധരെ പൂർണ്ണമായി തഴയാനും സർക്കാർ മുതിരുന്നുവെന്നത് ഒട്ടും അഭിമാനകരമല്ല.
സമിതിയുടെ നിർദ്ദേശങ്ങൾ ആർക്കുള്ളതാണെന്നോ എങ്ങനെ ഈ ലിപിപരിഷ്കാരം നടപ്പിലാക്കാമെന്നോ നടപ്പിലാക്കാൻ പറ്റുമെന്നോ ഉള്ള പരിഗണനകൾ ഇല്ല. 1971 ലെ പരിഷ്കരണത്തിൽ അത് പ്രത്യേകം പറയുന്നുണ്ടായിരുന്നു - അച്ചടിക്ക് മാത്രമാണെന്നും പഠിപ്പിക്കാനല്ലെന്നും.
ഈ നിർദ്ദേശങ്ങളുടെ ആഘാതമെന്താകും എന്നോ ആരെയൊക്കെ ഇത് ബാധിക്കുമെന്നോയുള്ള പരിഗണനകൾ കണ്ടില്ല. പ്രസിദ്ധീകരണരംഗത്തും മലയാളം സാങ്കേതികവിദ്യാരംഗത്തും വിദ്യാഭ്യാസരംഗത്തും നിരവധിയാളുകൾ ഉപജീവനമാർഗം നടത്തുന്ന ഒരു മേഖലയാണിത്. അവരെയൊന്നും പരിഗണിച്ചിട്ടില്ല.